What is different from Stata’s mdepriv?
Source:vignettes/what_is_different_from_stata.Rmd
what_is_different_from_stata.RmdThe mdepriv function is an adaptation in
R of a homonymous user-written
Stata command (Pi Alperin & Van
Kerm, 2009) for computing basic synthetic scores of multiple
deprivation from unidimensional indicators and/or basic items of
deprivation. To facilitate orientation and usage of
mdepriv, this R implementation
follows the Stata features as closely as
possible. There are only a small number of differences:
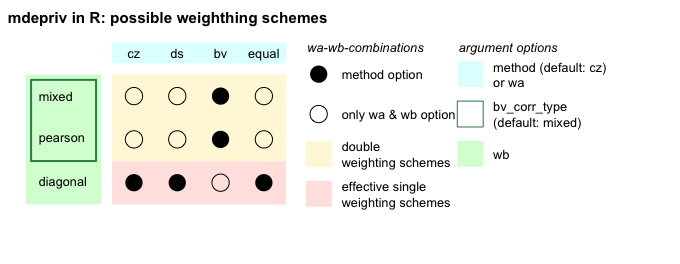
- The options for the second factor of the double weighting schemes
differ formally, but with virtually no practical consequences:
- In R as in
Stata, if the second weighting factor is set
to mixed, the correlation type for each pair
of items is automatically determined by the following rules:
- pearson: both items have > 10 distinct values.
- polyserial: one item has 10, the other > 10 distinct values.
- polychoric: both items have 10 distinct values.
- In R
tetrachoric, the appropriate correlation type
for pairs of binary items, is not available as the second weighting
factor. This is so because the R function
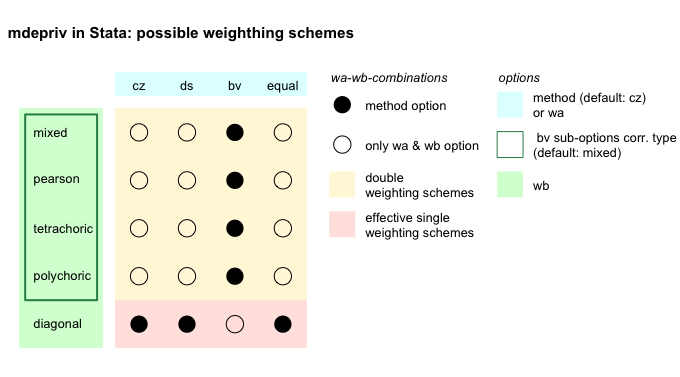
weightedCorr, on which the calculation of the second factor relies, treats tetrachoric correlations as polychoric. The different handling of tetrachoric correlations in R and Stata causes minuscule differences in the weights in models that include more than one binary item. - In Stata, if
polychoric is forced on (partly) continuous
pairs of items, it switches under the hood to
mixed. Thus
polychoric in Stata
is pointless as an enforecable option.
mdeprivin R does not reproduce this spurious option. - pearson is the only really enforceable correlation type in Stata and, therefore, it is maintained as such in R.
- diagonal, in both Stata and R, sets all off-diagonal elements to zero, making wb independent of any item correlations.
- In R as in
Stata, if the second weighting factor is set
to mixed, the correlation type for each pair
of items is automatically determined by the following rules:
mdeprivin R admits both non-integer and integer sampling weights for all methods. mdepriv in Stata admits integer frequency weights for all methods, as well as non-integer analytic weights for methods without double-weighting (which include method = cz, ds or equal).The option force allowing calculations in Stata, even if items are not limited to the [0, 1] range, is not implemented; such item sets produce invalid aggregate deprivation statistics. In R therefore, in preparation, any item with values on [0, max], where max > 1, has to be transformed. For more detailed information on suitable transformations have a look at the section ‘Details’ on
mepriv’s help page.
help("mdepriv")Differently from Stata, in R observations with missing item values have to be removed in preparation. Rationale and code can be found under section Handling Missing Values in the vignette Get Started with
mdepriv.-
Models with double-weighting work with an internal parameter known as rhoH. rhoH is determined by the central point in the largest gap in the ordered sequence of distinct correlation coefficients between all item / indicator pairs. As such, by default, rhoH is a data-driven quantity. The user has the option to set a value for rhoH; this is rarely called for, except when a constant rhoH is desired for the comparison of several such models. The implementation between Stata and R differs:
- By default, Stata uses -2 as starting
value for the computation of rhoH. In
R, the default value is NA, causing
mdeprivto calculate the data-driven value in models with double-weighting, or else leave it as NA. - Optional values in Stata must fall in the interval [-, +1]. In R, they are limited to [-1,+1], the range of correlation coefficients.
- By default, Stata uses -2 as starting
value for the computation of rhoH. In
R, the default value is NA, causing
The Stata option vec for passing user-defined weights to items is called user_def_weights for a more intuitive argument in R.
References
Pi Alperin, M. N. and Van Kerm, P. (2009), ‘mdepriv - Synthetic indicators of multiple deprivation’, v2.0 (revised March 2014), CEPS/INSTEAD, Esch/Alzette, Luxembourg. http://medim.ceps.lu/stata/mdepriv_v3.pdf (2020-01-02).